Custom Pricing - Sagemaker, etc.
Use this to register custom pricing for models.
There's 2 ways to track cost:
- cost per token
- cost per second
By default, the response cost is accessible in the logging object via kwargs["response_cost"] on success (sync + async). Learn More
Quick Start
Register custom pricing for sagemaker completion model.
For cost per second pricing, you just need to register input_cost_per_second.
# !pip install boto3
from litellm import completion, completion_cost
os.environ["AWS_ACCESS_KEY_ID"] = ""
os.environ["AWS_SECRET_ACCESS_KEY"] = ""
os.environ["AWS_REGION_NAME"] = ""
def test_completion_sagemaker():
try:
print("testing sagemaker")
response = completion(
model="sagemaker/berri-benchmarking-Llama-2-70b-chat-hf-4",
messages=[{"role": "user", "content": "Hey, how's it going?"}],
input_cost_per_second=0.000420,
)
# Add any assertions here to check the response
print(response)
cost = completion_cost(completion_response=response)
print(cost)
except Exception as e:
raise Exception(f"Error occurred: {e}")
Usage with OpenAI Proxy Server
Step 1: Add pricing to config.yaml
model_list:
- model_name: sagemaker-completion-model
litellm_params:
model: sagemaker/berri-benchmarking-Llama-2-70b-chat-hf-4
input_cost_per_second: 0.000420
- model_name: sagemaker-embedding-model
litellm_params:
model: sagemaker/berri-benchmarking-gpt-j-6b-fp16
input_cost_per_second: 0.000420
Step 2: Start proxy
litellm /path/to/config.yaml
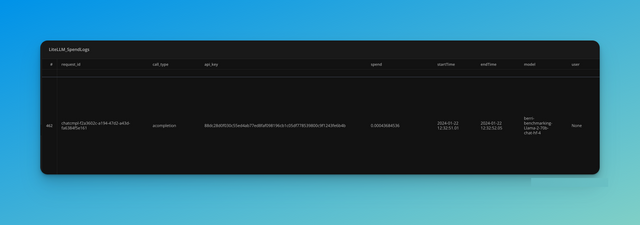
Step 3: View Spend Logs
Cost Per Token
# !pip install boto3
from litellm import completion, completion_cost
os.environ["AWS_ACCESS_KEY_ID"] = ""
os.environ["AWS_SECRET_ACCESS_KEY"] = ""
os.environ["AWS_REGION_NAME"] = ""
def test_completion_sagemaker():
try:
print("testing sagemaker")
response = completion(
model="sagemaker/berri-benchmarking-Llama-2-70b-chat-hf-4",
messages=[{"role": "user", "content": "Hey, how's it going?"}],
input_cost_per_token=0.005,
output_cost_per_token=1,
)
# Add any assertions here to check the response
print(response)
cost = completion_cost(completion_response=response)
print(cost)
except Exception as e:
raise Exception(f"Error occurred: {e}")
Usage with OpenAI Proxy Server
model_list:
- model_name: sagemaker-completion-model
litellm_params:
model: sagemaker/berri-benchmarking-Llama-2-70b-chat-hf-4
input_cost_per_token: 0.000420 # 👈 key change
output_cost_per_token: 0.000420 # 👈 key change